SQL技能是开发人员的基本技能,因此面试开发时,都会问到SQL相关的知识。
我在帮助公司招人时,也会出一道SQL的题目,来考察候选人的SQL技能。
下面这道题就是我面试时用到的,一个题,几个小题,难度逐步增大,考察候选人对于SQL的理解与应用。
表结构
有三张表:students学生表,courses课程表,scores成绩表,三个表的结构如下:
students:
courses: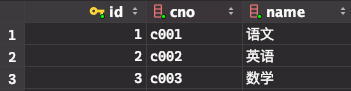
scores: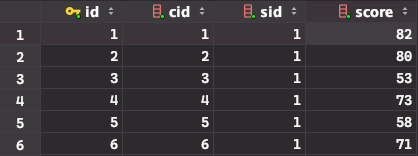
1. 输出成绩表,按照 姓名,课程名,成绩 的格式输出
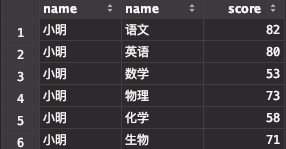
第一个题目很简单,要求输出学生姓名,课程名,以及每位同学的成绩,因此只需要把成绩表和学生表,课程表链接,分别获取学生名,课程名即可。
1 | select s.name,c.name,sc.score |
2. 输出每科的第一名,按照 课程名,学生名,成绩 的格式输出
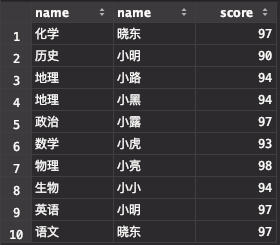
相对于第一个题目,难度稍加,但逻辑也非常简单。
很多同学在这个题目上折了,并不是因为不会写求第一名的SQL,而是因为其对SQL的group by理解不透彻导致的。
写出如下SQL:
1 | select s.name,c.name,max(sc.score) score |
这个SQL看上去好像没什么问题,成绩表连接学生表,连接课程表,分别拿到学生名,课程名,然后使用max函数求出每科的最高成绩,按科目分组。
可是,这个sql在实际运行时却报错:
1 | [42000][1055] Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'test.s.name' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by |
有的同学说,哎,这是mysql的一个sql_mode=only_full_group_by导致的,把这个模式改了就不报错,正常运行了。
真的是这样么?这么回答的同学基本是没理解sql里面group by。
group by 是分组操作,它要求被select的列要么在group by后面,要么在聚合函数里面,否则就会上面的错误。上面的错误是说s.name这个字段,没有在group by里面,也没有在聚合函数里面。
为什么会这样?
想一下group by的逻辑,它是分组操作,对于一个表中的数据,按照某个字段分组后,每个分组都会有多条记录,接下来的操作,是对每个分组的多条记录进行聚合操作,而不能单独对某个字段进行操作。因为这个字段和被分组的字段,不一定是一一对应的,如果不是一一对应的,单独select这个字段的时候,mysql怎么会知道要取这个分组中的哪一条呢?
这也就是为什么mysql中会有sql_mode这个设置,如果你确定你单独select的字段和要分组的字段是一一对应的,你可以打开这个设置,让mysql不再运行报错。但如果是某个同学对group by理解不深入,打开这个设置很容易导致,sql查询不报错,但是查出来的数据却不对,这种问题很难去排查,所以建议这个设置就是用only_full_group_by这个模式。mysql可以允许自己设置,postgresql直接就不允许用户自己设置,严格按照group by的逻辑来。
上面sql中,s.name, c.name两个字段,都不在group by后面或者不再聚合函数后面,因此运行肯定会报错。
正确的做法是,先从scores成绩表中查出每科第一名,然后再和scores自己连,查出对应的学生id,然后再和学生表,成绩表连接,得出学生名,课程名。
1 | select c.name,s.name,sc.score |
子查询中,根据cid进行分组,获取每个分组下的最大成绩(也就是每个科目的最高成绩),然后和scores,students,courses连接,查询出对应的学生名,课程名和成绩即可。
3. 输出每科成绩的前三名
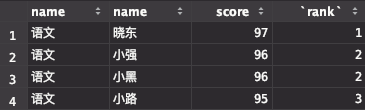
这个题目,相对于上面一个,又进一步。上面只是求每科的第一名,这个要求输出前三名。
这个也是group by ,然后limit 3么?limit 3的话只输出最终结果的3条,并不满足每个科目的前三名。
那该如何做呢?这里就得需要知道,mysql里的自定义变量了,使用自定义变量来统计排名。
怎么做呢?首先,我们先将每个科目按照成绩排名。
1 | select sc.cid, |
我们定义三个变量,rank,cid,pre来代指排名,当前的课程id,以及前一个分数。
sql中有一个case when的判断,这里能够判断的前提是,我们根据cid和score desc做了排序。
排序后,如果cid相等,但是分数不相等,那么排名+1。如果分数相等,且分数也相等,那么排名不变。否则排名设置为1。
上面查出的结果大概如下:
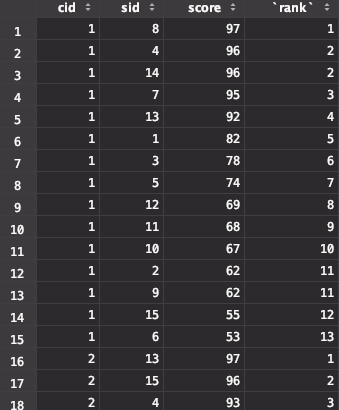
上面这个结构,不是最终结果,但确实至关重要的一步中间结果。
有了上面这个中间结果,我们就可以连接students,courses表,将学生名,课程名取出来。
1 | select c.name,s.name,tmp.score,tmp.`rank` |
4. 得过第一最多的同学
有了上面排名的这个sql,统计排名第一最多的就简单了,直接按照sid,统计一下每个人排名第一的课程有多少即可。
1 | select tmp.sid, count(1) as count |
但是,细想一下,好像这样做有点麻烦了,只是获取成绩第一的同学嘛,为啥要搞排名呢?除了第一,其他名词的排名不都浪费了么?
我们可以直接从成绩表中,按照课程分组,获取每个课程的最高成绩,然后回scores表查出每个课程最高成绩的同学的id,再统计个数不就完了嘛?
1 | select tmp2.sid, count(1) as count |