看到一篇文章,介绍在反爬虫过程中,前端工程师的各种脑洞,文章见这里。
文章里介绍了几个大的网站,在反爬虫过程中,采取的各式各样的策略,无不体现出前端工程师的奇葩脑洞。
还挺有意思的,就简单分析了一下,针对每个方案,看看有没有解决办法,于是整理成博客,记录一下。
1. 自定义字体形式
该方案是,自定义了一种字体,网页中使用乱码字符或者其他混淆字符,通过自定义字体的渲染成正确的显示数据。
代表网站有猫眼电影和去哪儿手机端。
1.1 猫眼电影
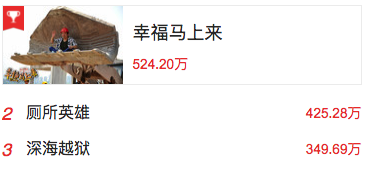
如上图,是猫眼首页今日票房栏的前10名统计(截图只截取了前三名),其中的票房数据,对爬虫来说是私密数据,于是,猫眼给“加密”了。
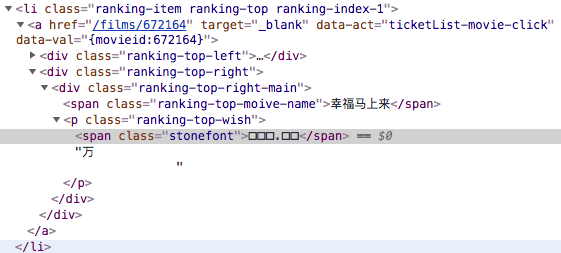
网页代码显示的是一堆乱码,都是方框。。。
我们通过浏览器的开发者工具查看该部分“方框”数字,发现是用了自定义的字体渲染成可视的数字的。


woff字体是网页开放字体格式,详细可参见 MDN。
我们把这个woff格式的字体文件下载下来,看一下这个自定义的字体里有啥奥秘呢?
这里推荐一个在线的字体编辑工具:百度字体编辑器。
将下载后的woff文件字体,在百度字体编辑器中打开:

好了,一目了然,这个字体文件里,采用随机的Unicode编码来定义了 0-9这几个数字以及一个空白符和一个小数点,而且数字定义的顺序不是固定的,Unicode编码也不是连续的。
也就是说,在HTML页面源码看到的方框,它的unicode应该和字体上的值是对应的,你可以用 charCodeAt()方法进行验证一下。
如果说,woff文件是固定的,那么其实问题很简单。但是,猫眼这个woff文件并不是固定的,而是随机的。
如果,woff字体文件里定义字体的顺序和实际数字顺序一致,或者其unicode值的顺序和真实数字是一致的,也简单。但是,顺序也是随机的。。。
所以,难道就真的没办法搞了么?
当然不!!!任何能在页面上显示的,都可以搞。
找到python的一个库 fonttools,可以解析成字体为 xml 文件,然后再根据xml里的信息找找:
其实百度字体编辑器代码是开源的,它其中依赖了一个核心库 fonteditor-core ,这个库应该也能解析字体数据,但是我在实验时,老是报错解析错误,不知为何,有兴趣的小伙伴可以自行研究一下,并分享一下研究成果,谢过。
1 | from fontTools.ttLib import TTFont |
生成的xml文件,有两部分很重要:
1 | <GlyphOrder> |
第一部分是字体概览,定义了字体集中的name,注意,这里id和实际数字并无关系,并不是实际的数字0,1,2…等等。name是采用unicode定义的 ,和在百度字体编辑器中的正好是一致的。
1 | <TTGlyph name="uniF4CA" xMin="0" yMin="-13" xMax="511" yMax="719"> |
第二部分是具体每个字体的座标集合信息,这里我只摘录了其中的一个字符F4CA的信息,我们多刷新两次页面,拿两个不同的woff文件,转换成xml文件,对比会发现,虽然每次定义的unicode不同,顺序是随机的,unicode也不连续,但是,但是,但是,有一样是相同的,那就是上面第二部分字体的座标信息。为啥一样呢?因为每个数字样式是固定的,所以画出图来座标必定是一样的。
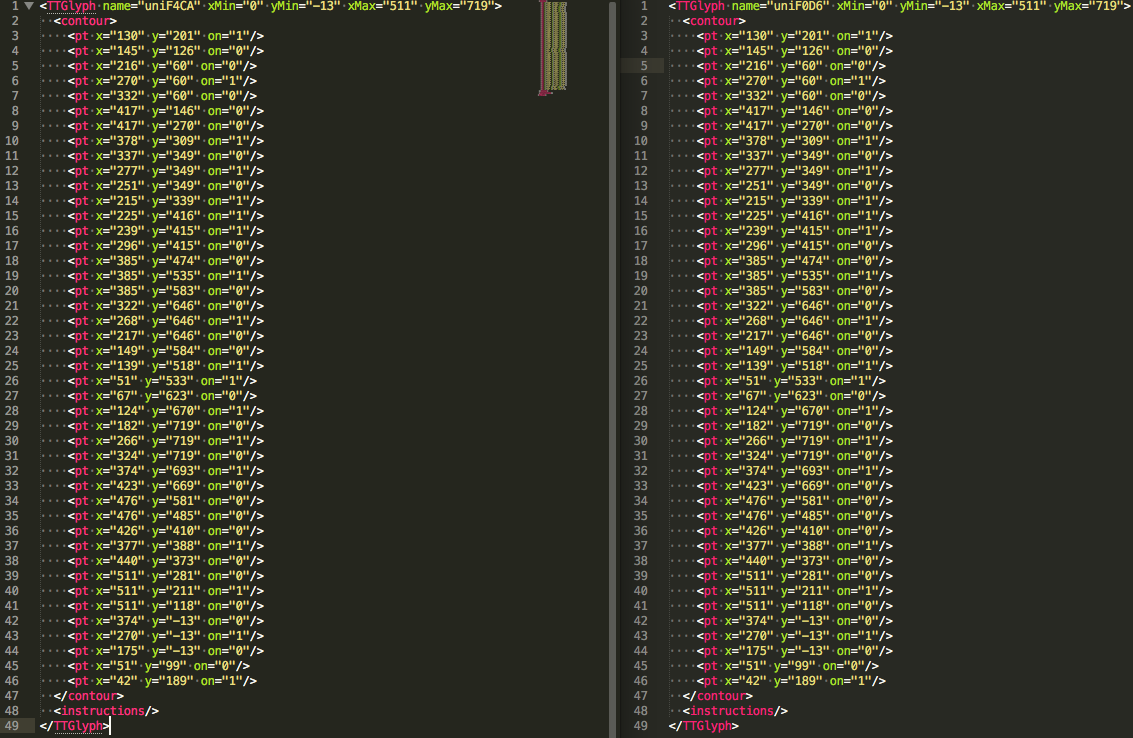
好了同志们,到这里,基本就明朗了,我们可以人工先把几个数字的座标点进行标记,然后每次刷新时,拿到新的woff字体时,通过fonttool将字体转换成xml格式,根据座标点信息,判断其uncode值分别是多少。然后再将代码中的“方框”转换成真实数字即可。
1.2 去哪儿手机端网页
去哪儿手机端采用的方案和猫眼类似,都是用的自定义字体进行混淆。
但去哪儿采用的是ttf格式的字体文件。这是不同点一。
而且,去哪儿自定义的字体,采用的unicode也比较简单,看下面:

去哪儿直接用的真实数字的uncode进行编码,只不过顺序和真实数字不是一一对应的,也就是说,网页源码中如果是 ‘183’,实际显示的数字却是 ‘361’。
而且每次好像也是不一样的。不过没关系,只要能用 fonttool 将其转换成xml文件,拿到里面的座标数据,那么,没跑。
1.3 起点中文网
有一个小说阅读网站,叫起点中文网,也是采用了自定义字体的形式,这也是在cnode上有一个小伙伴提问的,我这次也看了一下。
不看不知道,一看吓一跳,拿到源码里的“方框字”后,看了一下其 unicode 编码,全是一个unicode编码,如下面:
1 | node test.js |
其中第一行94.37是真实显示的阅读数,后面的每一行是一个方框字对应的unicode编码,当我看到结果是,崩溃了,都是一样的,什么鬼。。。 同一个字符编码,能渲染出不同的数字来???
怎么套路和猫眼和去哪儿不一样呢?
从源码中,看到,这段阅读数加密的数字,使用了css 类名为 zxJBLkdl,顺着源码,找到类 zxJBLkdl 的定义部分,有这么一段代码:
1 | <p> |
在这段代码里发现了猫腻,其采用的也是随机字体的形式,比如此次刷新时的字体叫zxJBLkdl.woff,这不重要。
重要的是 <span class="zxJBLkdl">𘝕𘝘𘝚𘝕𘝙</span>这一行,这是啥,这是使用了html转义字符输出了几个不知名的方块字,然后通过字体再渲染出真实的数字显示。
这里和普通的 <等不同,这里叫做实体编号,实际转义字符都要转成实体编号才能被浏览器识别,具体请参阅这里。
可是为啥我拿到的unicode是一样的呢?
答案还是得从字体文件里找。使用fonttool将字体文件转换成xml,然后你就找到了下面的代码:
1 | <GlyphOrder> |
太明目张胆了,直接用英文来命名数字,再继续找这几个英文数字的定义,找到如下代码:
1 | <cmap_format_12 platformID="3" platEncID="10" format="12" reserved="0" length="148" language="0" nGroups="11"> |
这里应该就是每个字符和其十六进制编码之间的关系了。将上面的转义编号的数字部分转换成十六进制,正好就是这十六进制的编码,因为这转义字符是“自定义的”,因此浏览器不能识别,只显示方框,估计在拷贝的过程中发生异常,浏览器不能识别具体的字符,都是按照方框去拷贝的,所以出来的unicode都是一样的。
到这里起点中文网的过程也明朗了,其实质和猫眼也是一样的,只是过程和形式不大一样而已。
1.4 小结
采用自定义字体的网站,思路都一致。
后端搭一套字体生成接口,随机生成一个woff字体,然后返回这个字体文件,以及各个数字的unicode对应关系,前端页面进行数据填充即可。
基本采用自定义字体的方式,都可以使用上面的思路去破解,先拿到一个字体文件,然后使用fonttool转换成xml,人工拿到每个数字的座标,然后就可以写程序,当拿到新的字体文件时,通过座标信息去判断每个数字到底是多少。
还有一种方案,使用无头浏览器进行截图,然后使用OCR工具进行文字识别,但这种方案问题在于,OCR识别存在一定的错误率,因此并不完美。这里就不说了。
2. 元素定位覆盖
这种方式太有意思了,给两套数据,前面一套假的,后面一套真的,然后显示时,通过css定位,将假的数据覆盖掉,只显示真实数据。
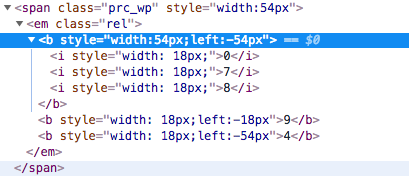

这个代码块里面,第一个 <b> 元素中有三个<i>元素,其中0和8是假的,是被后面的两个<b>元素的9和4覆盖掉了,显示的真实数据是 479 。
这种方式很有意思,但在反爬难度上,和第一种采用自定义字体的方式,略微低一点,感觉有点骗小孩的意思。
我们可以根据第一个b元素的宽度,以及后面b元素的宽度和偏移量来计算,拿到真正的值(实际浏览器不就是这样工作的么)。
比如上面这个,第一个b元素的宽度是54px,左偏移 -54px,第二个b元素为18px,左偏移-18px,那么很明显覆盖的是第三个数字嘛,第三个b元素左偏移-54px,覆盖的是第一个数字,这样完全可以写个程序自动判断,拿到真实数字。
这个方式没有写具体代码,但代码应该不难写,有兴趣的可以试试。
3. 背景图拼凑
还有一种形式是,使用背景图片,然后给位置,截图,拼凑出真实的数字。
如imweb这篇文章里提到的美团这种方式。但是我没找到美团哪个页面现在是这样的,应该是美团现在改版了,现在都是直接显示数字。
这种方式,和上面元素定位覆盖差不多的思想,但稍微复杂点,先把背景图片拿下来,然后再解析html拿到具体的 background-position具体的值,使用能够解析图片的类库进行截取数字,拿到的数字是图片格式的,没办法,这种只能在通过一次OCR识别了,图片,真的没办法。
因为是图片,所以与其那么复杂去解析每个位置是啥数字,倒不如直接通过无头浏览器进行截图,然后通过OCR识别来的直接,因为浏览器显示的就是图片,只能进行文字识别这条路了。
这种方式在破解时复杂点,还会存在一定的错误识别率,其实还是一种不错的反爬前端方案。但有一点不好的地方在于,由于是使用的图片,所以在显示上,不如文字那么清晰,而且在浏览器缩放时,也会有一定的模糊,给用户的体验会不好,不如文字清晰。
4. 伪类元素代替
汽车之家现在使用的是伪类元素,将词组拆开,使用伪类元素代替。
这种方式在搞起来,比上面字体要难感觉。
拿汽车之家举例,伪类的类名是随机的,而定义伪类的css样式,是js动态生成的,搞起来比较麻烦。
没有爬汽车之家的需求,不搞了,我在网上找到一篇关于搞汽车之家这种方式的文章,有兴趣的同学可以看下: 反爬虫破解系列-汽车之家利用css样式替换文字破解方法
从最终的结果来看,是js动态获取要替换的问题,然后动态替换了问题。而且现在汽车之家又升级了,要替换的文字也是动态获取的,没有任何标志,所以在实际操作起来,难度还是蛮大的。
汽车之家的前端,你可以的,佩服。。。
有兴趣的同学真的可以搞一下,搞定这个真的很有成就感。
5. 添加干扰字符并隐藏
这类有微信公共号的文章以及全网代理ip这个网站。
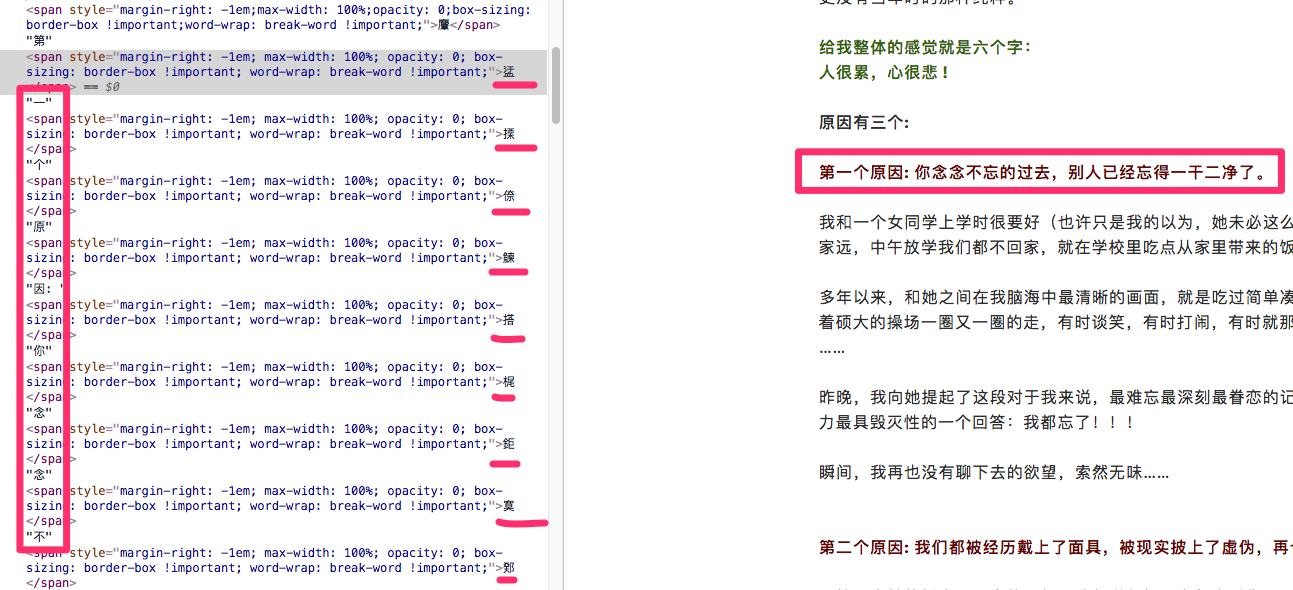
微信公众号里面,左侧下划线的部分文字为干扰文字,使用css的透明度(opacity)将透明度设置为0隐藏显示。
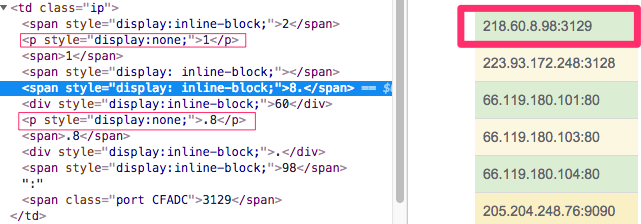
全网代理ip这个网站,左侧画细框的部分为干扰文字,使用css的display:none隐藏不显示。
这种方案的话,需要解析每个dom元素,并根据其css样式进行选择正确的字符进行拼装。难度应该不大,没具体实施。
6. 总结
这个周末主要的精力放到了搞自定义字体部分了,觉得这个特有意思,因为之前也遇到过,当时不知道咋弄。
爬虫与反爬向来都是,道高一尺,魔高一丈。在反爬方面,除了在后端上设置反爬策略,如限制ip访问频率,限制登录用户访问频率等等,前端在反爬上,也绞尽脑汁做了不少动作。
还是那句话,反爬做的就是,不断提升爬虫解析出正确数据的成本,但没办法真正防止爬虫。
对于爬虫来说,任何你能从浏览器上看到的数据,爬虫都能拿到,只是在拿数据时,难以程度有所不同而已。
希望该文章能给大家带来一些思路,帮助大家在爬虫与反爬虫过程中,作出更多有创新性的工作。